
Gedmatch has several admixture calculators. Do you know which gedmatch admixture calculator you should choose to determine your ancestry composition? Before we get into the details, lets first try and understand what Admixture means?
What is admixture?
Admixture is a methodology of determining presence/absence of DNA segments from different populations within an individual. I am going to use a simple example to explain gedmatch admixture calculators.
Imagine you ordered 4 pizzas – one each from Papa Johns, Pizza Hut, Domino’s and Sbarro. Now you have been assigned the task of re-constructing a pizza from the 4 pizzas that you received. So you take one slice from each Pizza and assemble your own Pizza- name it Pizza-1. Once you have assembled it, you now ask your guests to guess which Pizza belongs to which Company? Your guests then take a look at the original pizzas from each of the 4 companies and then try to guess that 25% came from Papa John’s, 25% from Pizza Hut, 25% from Domino’s and the other 25% from Sbarro. Admixture genetics is very similar to the Pizza example.
This was a simplistic example as there was only one Pizza from each Company. But imagine there were different variations and toppings of the Pizzas, then the task would become more challenging. That’s why scientists created a software or algorithm to simplify and predict more complex ancestry compositions.
What does admixture software do?
The admixture software is typically built based on a mathematical model called Maximum Likelihood. Genetic data from multiple populations (Pizzas) are used to train and recognise patterns so when you give a sample from an unknown population, it tries to predict the ancestry composition based on what it has learned. That’s why quality of data becomes extremely important in this exercise. Let’s go back to the pizza example. The software is shown various pizzas from each company and is trained to recognise patterns from each of their pizzas. Imagine if you used garlic sticks from a company among other Pizzas to train the software. It is highly likely that the model produced would lead to inaccurate results.
Gedmatch admixture analysis
In the above pizza example, while the algorithm/software recognises patterns in each population, it does not use these patterns to differentiate from other populations. It just finds the best fit with a particular population. Gedmatch, the popular online DNA matching service uses several admixture models, that I am sure you’ve heard of such as Dodecad, Harappa, Eurogenes, MDLP etc. Now you may be wondering what exactly these models are and why are there so many of them. In order to understand this complex problem, let’s head back to the Pizza scenario.
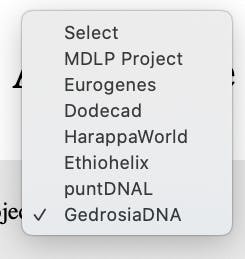

You constructed Pizza-1 from four companies. Now your Mom constructed Pizza-2 (different slices from each company) and similarly you sister constructed another Pizza-3. You now have 3 recipes of making Pizzas and you store them so that next month when you want to construct Pizza-2, you just use that particular recipe. Gedmatch admixture models are like recipes except they have been put together by various researchers or genealogy enthusiasts across the globe. These models (calculators) are used to determine the ancestry composition from your DNA. So selecting the right model becomes important when you are trying to determine your ancestry proportions.
Which is the best Gedmatch admixture calculator (model/recipe)?
Do you remember Pizza-1 and the various slices that were used to make Pizza-1? Let’s say you were given the recipe for Pizza-1 but now you had slices from a 5th company (Cici’s). Since your recipe recognises only 4 companies, this 5th company is foreign as far the recipe is concerned. Admixture models are no different. They work well if they recognise DNA from a dataset that they have built on. The MDLP project for example has 22 components. While it may be accurate for these 22 populations, it may not be accurate if your DNA has segments that come from a 23rd component (geographical region). So the composition calculated is as good as the data that was used to build the model.
| Gedmatch calculator | Relevant Population |
|---|---|
| MDLP Project | Has 22 components from various parts of the world and is best suited if you want to know your global ancestry composition. |
| Dodecad | Middle East, Africa, Eastern Europe and East Asia |
| Ethio-helix | Best suited for deeper African ancestry compositions |
| Eurogenes | Eastern Europe, Western Europe and West Asia |
| Harappa World | South Asian |
| puntDNAL | Western Europe |
So are these Gedmatch admixture models accurate?
Yes! When it comes to that particular dataset, they are accurate. But are they accurate when you ask it predict a new population that the model has not seen. Likely not! Accuracy can broadly be determined as follows:
- How robust is the dataset? – In probability CLT (Central Limit Theorem) states that if you take sufficiently large random samples with replacement, then the sample mean is almost equal to the actual mean. In short, larger the dataset, better the accuracy of the model.
- What population labels were used? – This is another important component when trying to train a particular admixture model. How was the population labeled? For example, the aborigines in Australia and the recent immigrants into the Continent. Would they both be labeled Australians? This might be an obvious example but is necessary when it comes to sensitivity of the model.
- What mathematical algorithm was used? Companies like Ancestry and 23andMe have been using Machine Learning to determine ancestry compositions because they are far superior to the older algorithms like admixture. Machine learning algorithms are fast and consume far less computational resources compared to the older generation admixture algorithms.
Which Gedmatch admixture calculator worked for you? Share your experience.

